AI 4 Coding
Day 2. Advanced features: #tools, MCP, instructions, /prompts, @agents, and more…
2026-04-23
Tools in Positron
Tools extend agents with specialized functionality: searching code, running commands, fetching web content, or invoking APIs.
Three types of tools:
- Built-in tools —
#codebase,#problems,#web,#search,#edit - MCP tools — from installed MCP servers
- Extension tools — contributed by VS Code / Positron extensions
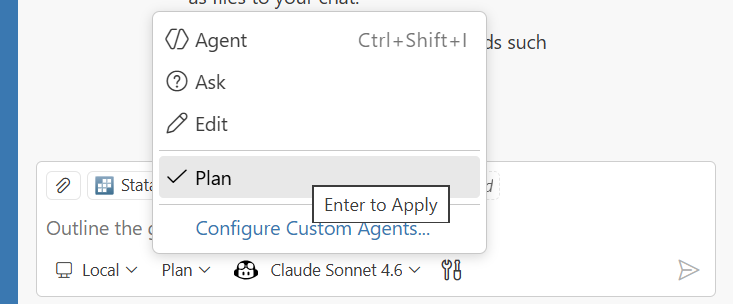
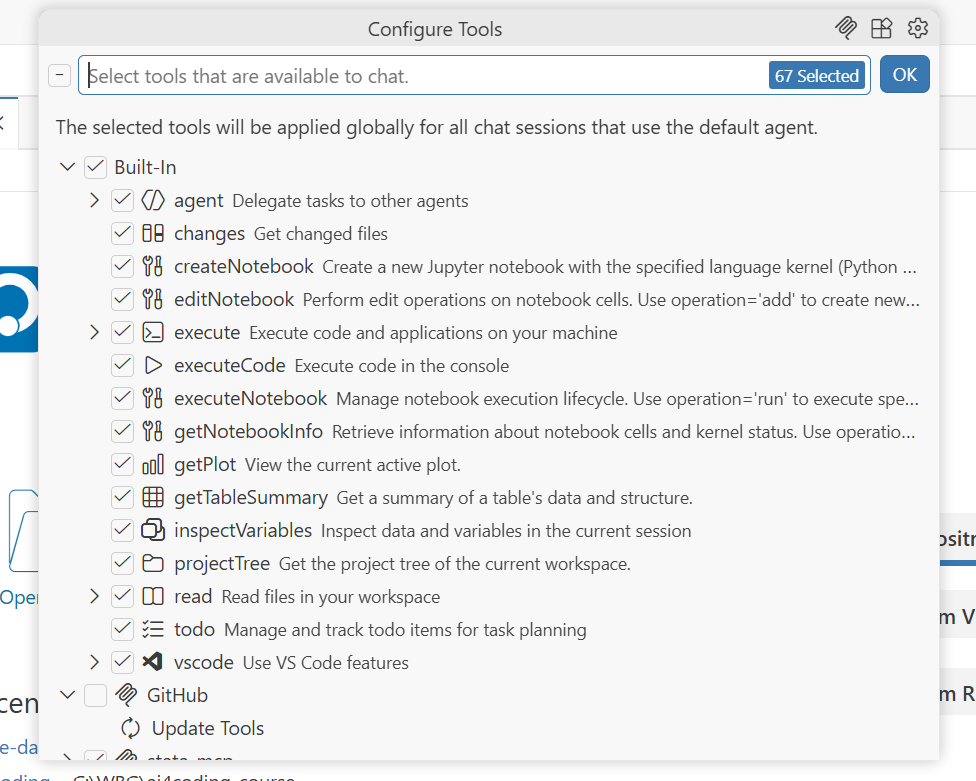
Toggle tools per-request via the Configure Tools button in the chat input.
![]()
What is MCP?
Model Context Protocol (MCP) is an open standard for connecting AI applications to external systems: a USB-C port for AI.
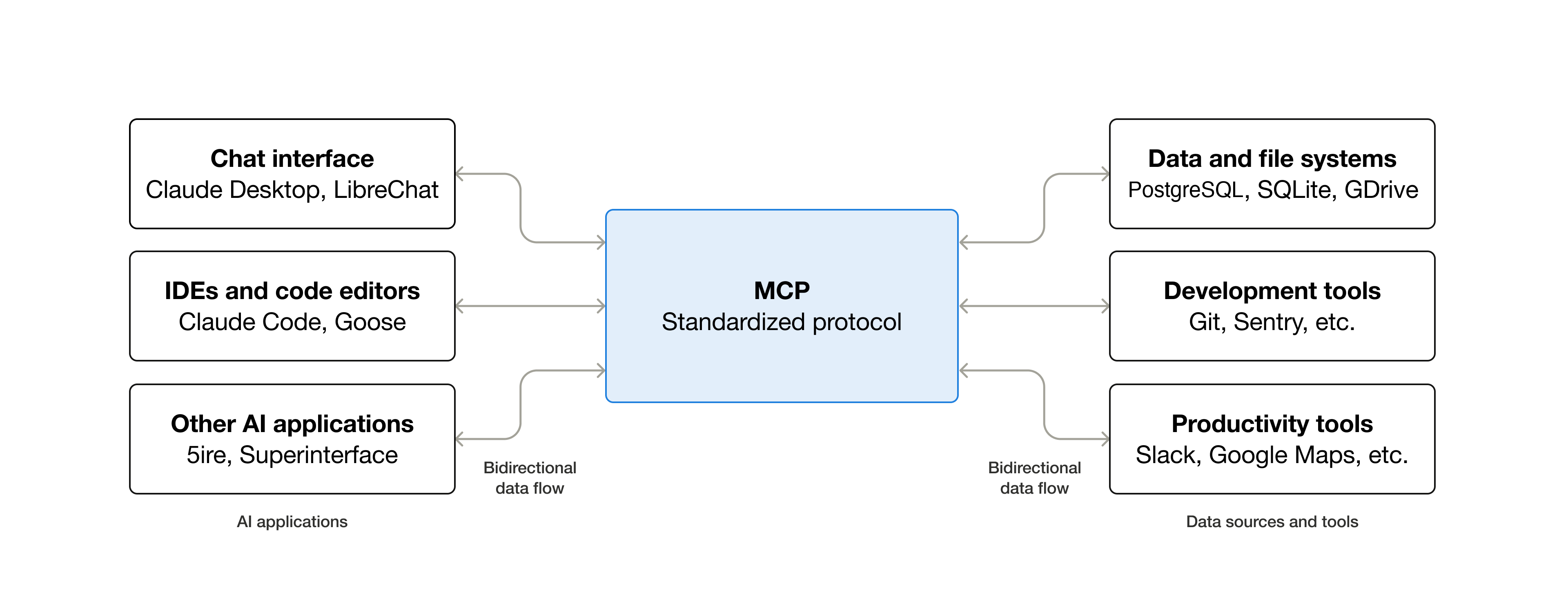
MCP servers expose specialized Tools (executable functions), Resources (contextual data), and Prompts (reusable templates) to the AI agent.
MCP Servers in Positron
- Only by configuring
.vscode/mcp.jsonthrough Command Palette —MCP: Add Server. - WB Disables: Extensions view — search
@mcpand install from the MCP server gallery

Demo: Stata MCP
No need to install any additional software, only Stata for Positron
ntluong95/positron-statathat we installed on Day 1.Configure MCP server connection as described in the previous slide.
Start MCP server locally by pressing
StartUse
#stata_run_fileor#stata_run_selectionin the chat as a new tool.Observe the difference in executing code via the MCP tool.
The Agent Loop
Every agent follows the same iterative cycle — Understand → Act → Validate — until the task is done.
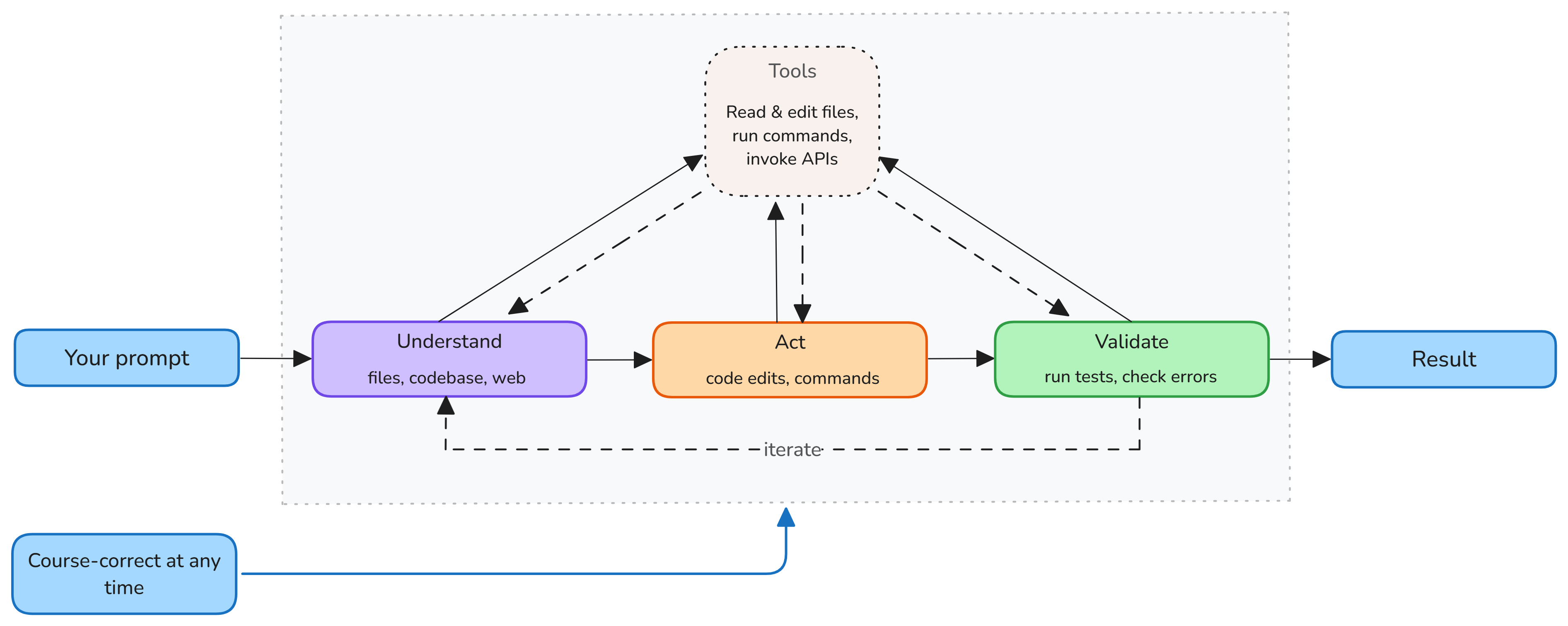
You stay in control by:
- Redirecting requests, adding context, or stopping at any time.
- Accepting or rejecting tool calls, and providing feedback.
Three stages:
- Understand — reads files, searches the codebase, looks up docs
- Act — edits code, runs commands, calls tools / MCP servers
- Validate — runs tests, checks errors, self-corrects
At each step the model picks the next action. Tool outputs feed the next iteration.
Agent Types
Agents run in different environments depending on when you need results and how much oversight you want.
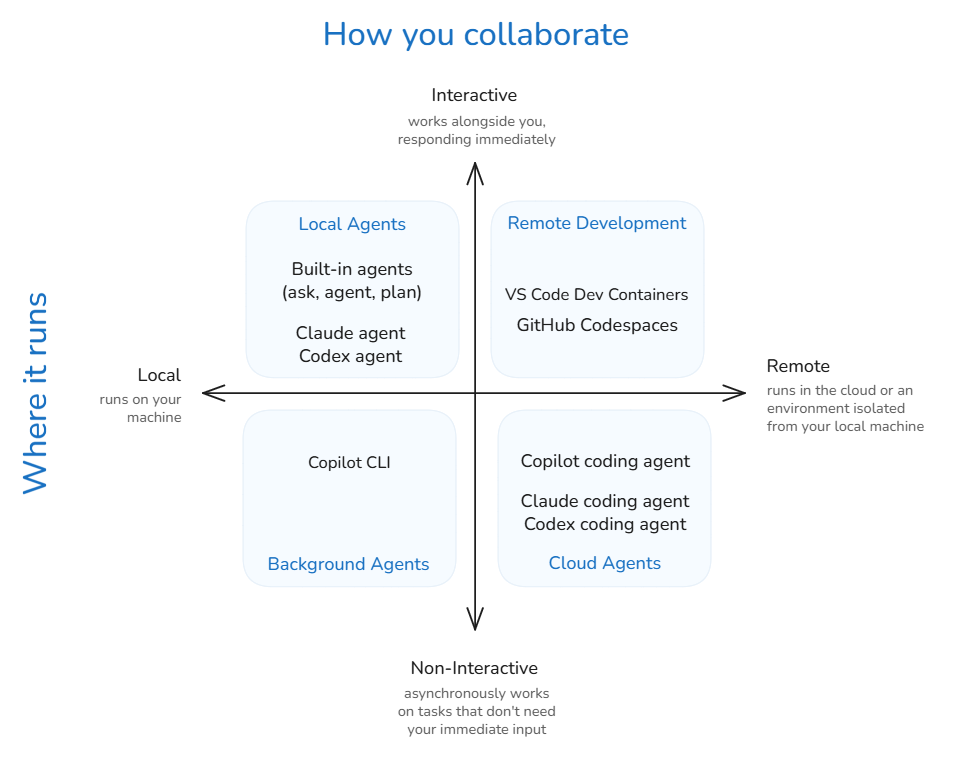
| Type | Where | Interaction |
|---|---|---|
| Local | Your machine | Interactive in IDE |
| Background | Your machine | Autonomous, async |
| Cloud | GitHub infra | Autonomous, remote |
Choosing the right type:
- Quick fix / refactor → Local agent
- Long build / migration → Background agent
- CI/CD, issue triage → Cloud agent (GitHub Copilot coding agent)
Planning Mode
For complex tasks, jumping straight into code generation leads to wrong architectural decisions. Plan mode researches and designs before writing a single line of code.
4-phase workflow:
- Discovery — read-only research using codebase analysis & tools
- Alignment — clarifying questions to resolve ambiguities
- Design — structured implementation plan drafted
- Refinement — iterate on the plan with your feedback